
스트림으로 데이터 수집
업데이트:
컬렉터
- 정의
- collect : Collector를 매개변수로 하는 스틀미의 최종 연산
- Collector : Collect에서 필요한 메서드를정의해놓은 인터페이스
- Collectors : 다양한기능의 Collector를 구현한 클래스 제공
- Collectors 유틸리티 클래스는 자주사용하는 컬렉터 인스턴스르 손쉽게 생성할 수 잇는 정적 팩토리 메서드를 제공한다.
- 함수형 프로그밍에서는 무엇을 원하는지 직접 명시를 할 수 있어서 어떤 방법으로 이를 얻을지는 신경 쓸 필요가 없다.
- 고급 리듀싱 기능을 수행하는 컬렉터
- collec로 결과를 수집하는 과정을 간단하면서도 유연한 방식으로 정의할수 있는 점이 컬렉터의 최대 강점이다.
- 스트림에 collect를 호출하면 스트림의 요소에(컬렉터로 파라미터화된) 리듀싱 연산이 수행된다.
- 명령형 프로그래밍에서는 직접 구현해야 했던 작업이 자동으로 수행된다.
- 미리 정의된 컬렉터
- Collectors에서 제공하는 메서드의 기능은 크게 세가지로 구분할 수 있다.
- 스트림 요소를 하나의 값으로 리듀스하고 요약
- 요소 그룹화
- 요소 분활
리듀싱과 요약
- 컬렉터로 스트림의 항목을 컬렉션으로 재구성 할 수 있다. 컬렉터로 스트림의 모든 항목을 하나의 결과로 합칠 수 있다는 말이다.
- ex) counting()이라는 팰토리 메서드가 반환하는 컬렉터로 메뉴에서 요리 수를 계산한다.
- long howManyDishes = menu.stream().collect(Collectors.countiong()) » long howManyDishes = menu.stream().count
- 다음처럼 불필요한 과정을 생략할 수 있다.
- 최대값과 최소값 검색
- Colectors.maxBy, Collect.minBy
- 요약 연산
- 단순 합계 : Collectors.summingInt, summingLong, summingDouble
- 평균값 : Collectors.averagingInt, averagingLong, averagingDouble
- 두개 이상의 연산을 사용할땐 팩토리메서드 summarizingInt가 반환하는 컬렉터를 사용할수 잇다.
// 출력시 해당 클래스로 모든 정보(합계, 카운트, 평균, 최소, 최대)가 수집된다. IntSummaryStatistics menuStatistics = menu.stream().collect(summarizingInt(Dish::getCalories));
- collec와 reduce
- 같은 기능은 구현할수 있으나 collect 메서드는 도출하려는 결과를 누적하는 컨테이너를바꾸도록 설계된메서드인 반면 reduce는 두 갑슬 하나로 도출하는 불변형 연산이라는점에서 의미론적 문제가 일어난다. 가변 컨테이너 관련 작업이면서 병령성을 확보하려면 collect 메서드로 리듀싱 연산을 구현하는 것이 바람직 하다.
- 컬렉션 프레임 워크유연성
- counting 컬렉터도 세 개의 인수를 갖는 reducing 팩토리 메서드를 이용해서 구현할 수있다.
- 제네릭 와일드카드 ‘?’
- 위 코드에서 ?는 컬렉터의 누적자 형식이 알려지지 않았음을, 누적자의 형식이 자유로움을 의미한다.
// 스트림의 Long 객체형식의 요소를 1로 변환한 다음에 모두 더한다. public static <T> Collector<T, ? Long> counting() { return reducing(0L, e -> 1L, Long::sum); }
- 위 코드에서 ?는 컬렉터의 누적자 형식이 알려지지 않았음을, 누적자의 형식이 자유로움을 의미한다.
그룹화
- Collectors.groupingBy
- 데이터 집합을 하나 이상의 특성으로 뷴류해서 그룹화 할때 팩토리메서드 Collectors.groupingBy를 이용하면 쉽게 그룹화 할 수 있다.
- 아래의 코드는 각 요리의 Dish.type과 일치하는 모든 요리를 추출하는 함수를 groupingBy 메서드로 전다했다. 이 함수를 기준으로 스트림이 그룹화 되므로 이를 분류함수라고 부른다.
Map<Dish.type, List<Dish>> dishesByType = menu.stream().collect(groupingBy(Dist::getType));
- 필요에 의해서 특정 조건에 따라 구분이 필요한 경우 메서드 참조 대신 람다 표현식으로 필요한 로직을 구할수 있다.
public enum CaloricLevel {DIET, NORMAL, FAT} Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect( groupingBy(dish ->{ if(dish.getCalories <= 400) return CaloricLevel.DIET; else if(dish.getCalories <= 700) return CaloricLevel.NORMAL; else return CaloricLevel.FAT; })); - 그룹화된 요소 조작
- 특정 조건에 해당 하는 요소만 필터를 할때 그룹화 하기전에 프레디 케이트로 필터를 적용하면 조건에 해당하지 않는 키 자체는 없어져 버린다.
- 위 방식을해결하기위해 Collectors 클래스는 일반적인 분류 함수에 Collector 형식의 두번째 인수를 갖도록 groupingBy 팩토리 메서드를 오버로드해서 문제를 해결한다.
//두번째 Collector 안으로 필터 프레디 케이트를이동함으로 문제를 해결한다. Map<Dish.Type, List<Dish>> caloricDishesByType = menu.stream().collect( groupingBy(Dish::getType, filtering(dish -> dish.getCalories() > 500, toList()))); - filtering 메소드는 Collectors 클래스의 또 다른 정적팩토리 메서드로 프레디케이트를 인수로 받는다.이 프레디케이트로 각 그룹의 요소와 필터링 된 요소를 재 그룹화 한다. 이렇게 해서 목록이 비어있어도 항목이 추가되어 같이 표시된다.
- 다 수준 그룹화
- 두 인수를 받는 팩토리 메서드 Collectors.groupingBy를 이요해서 항목을 다수준으로 그룹화 할 수 있다. 이 함수는 일반적인 분류 함수와 컬렉터를 인수로 받아 바깥쪽 groupingBy 메서드에 스트림의항목을 분류할 두번째 기준을 정의하는 내부 groupingBy를 전달해서 두 수둔으로 스트림의 항목을 그룹화 할 수 있다.
- 외부맵은 첫 번째수준의 분류 함수에서 분류한 키값을 갖는다. 그리고 외부 맵의 값은 두 번째 수준의 분류 함수 기준을 키 값으로 갖는다.
- groupingBy 연산을버킷으로 생각하면 되고 첫번째는 각 키의 버킷을 만들고 그리고 준비된 각각의 버킷을 서브스트림 컬렉터로 채워가기를 반복하면서 n 수준 그룹화를 달성한다.
Map<Dish.type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel = menu.stream().collect( groupingBy(Dish::getType, // 첫번째 수준의 분류 함수 groupingBy(dish -> { if(dish.getCalories() <= 400) retur CaloricLevel.DIET; else if(dish.etCalories() <= 700) return CaloricLevel.NORMAL; else return CaloricLevel.FATl }) ) ); - 중첩 컬렉터의 작업
- groupingBy는 가장 바깥쪽에 위치하면서 요리의 종류에 따라 메뉴 스트림을 세 개의 서브스트림으로 그룹화 한다.
- groupingBy 컬렉터는 collecthingAndThen 컬렉터를 가싼다.따라서 두 번째 컬렉터는 그룹화된 세 개의 서브스트림에 적용된다.
- collectiongAndThen 컬렉터는세 번째 컬렉터 maxBy를 감싼다.
- 리듀싱 컬렉터가 서브스트림에 연산을수행한 결과에 collectiongAndthen의 Optiongal::get 변환 함수가 적용된다.
- groupingBy 컬렉터가 반환하는 맵의 분류 키에 대응하는 세 값이 각각의 요리 형식에서 가장 높은 칼로리다.
Map<Dish.type, Dish> mostCaloricByType = menu.steam() .collect(groupingBy(Dish::getType, //분류 함수 collectiongAndThen( maxBy(comparingInt(Dish::getCalories)), //감싸인 컬렉터 Optional::get))); //변환 함수
-분할
- 분할 함수
- 분할 함수라 불리는 프레디케이트를 분류 함수로 사용하는 특수한 그룹화 기능이다.
- 분할 함수는 불리언을 반환하므로 맵의 키 형식은 Boolean이다.
- 결과적으로 그룹화 맵은 최대(true, false) 두 개의 그룹으로 분류 된다.
Map<Boolean, List<Dish>> partitionedMenu = menu.stream().collect(partitioningBy(Dish::isVegetarian)); // 분할 함수 List<Dish> vegetarianDishes = partitionedMenu.get(true);
- 장점
- 참, 거짓 두 가지 요소의 스트림 리스트를 모두 유지한다는 것이 장점이다.
- 컬렉터를 두 번째 인수로 전달 할 수 있는 오버로드된 버전의 partitioningBy 메서드도 존재한다.
Map<Boolean, Map<Dish.type,List<Dish>>> vegetarianDishesByType = menu.stream(). collect( partitioningBy(Dish::isVegetarian, groupingBy(Dish::gettype)); //두번째 컬렉터 )Collectors 클래스의 정적 팩토리 메서드
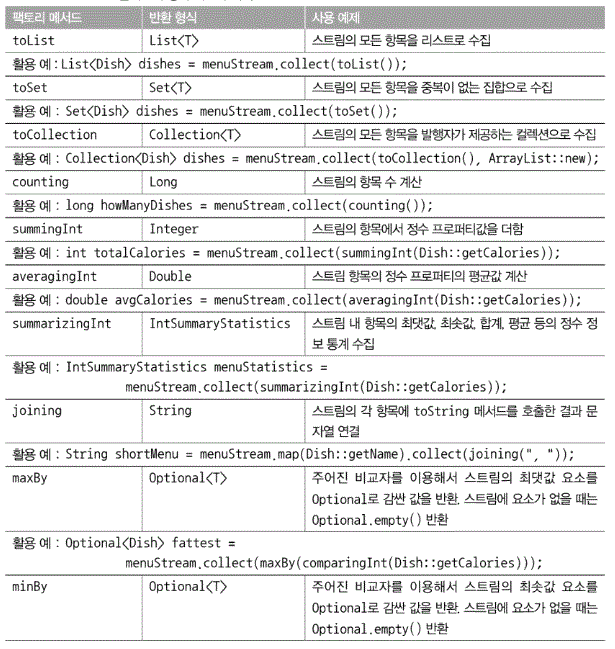

Collector 인터페이스
- Collector 인터페이스는 리듀싱 연산(즉, 컬렉터)을 어떻게 구현할지 제공하는 메서드 집합으로 구성된다.
- 아래의 코드는 인터페이스의 시그니처와 다섯 개의 메서드 정의를 보여준다.
- T는 수집될 스트림항목의 제네릭 형식이다.
- A는 누적자, 즉 수집 과정에서 중간 결고를 누적하는 객체의 형식이다
- R은 수집 연산 결과 객체의 형식(대부분 컬렉션 형식) 이다.
public interface Collector<T, A, R>{
Supplier<A> supplier();
Biconsumer<A,T> accumulator();
Function<A,R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}
- supplier 메서드 : 새로운 결과 컨테이너 만들기
- supplier 메서드는 빈 결과로이루어진 Supplier를 반환해야 한다.
- Supplier는 수집 과정에서 빈 누적자 인스턴스를 만드는파라미터가 없는 함수로 간단히 말해 매개값이 없고 호출한 곳으로 데이터를 리턴(공급) 하는 역활을 한다.
public Supplier<List<T>> supplier(){ return () -> new ArrayList<T>(); } public Supplier<List<T>> supplier(){ return ArrayList::new; }
- accumulator 메서드 : 결과 컨테이너에 요소 추가하기
- 리듀소를싱 연산을 수행하는 함수를 반환한다.
- 함수의 반환값은 void로 요소를 탐색하면서 적용하는 함수에 의해 누적자 내부상태가 바뀌므로 누적자가 어떤 값일지 단정 할수 없다.
public BiConsumer<List<T>, T> accumulator(){ return (list, item) -> list.add(item); } public BiConsumer<List<T>, T> accumulator(){ return List::add; }
- finisher 메서드 : 최종 변환값을 결과 컨테이너로 적용하기
- 스트림 탐색을 끝내고 누적자 객체를 최종 결과로 반환하면서 누적 과정을 끝낼 때 호출할 함수를 반환해야 한다.
- List에서누적된 것을그대로 반환한다.
public Function<List<T>, List<T>>finisher(){ return Function.identity(); }
-
순차 리듀싱 과정의 논리적 순서
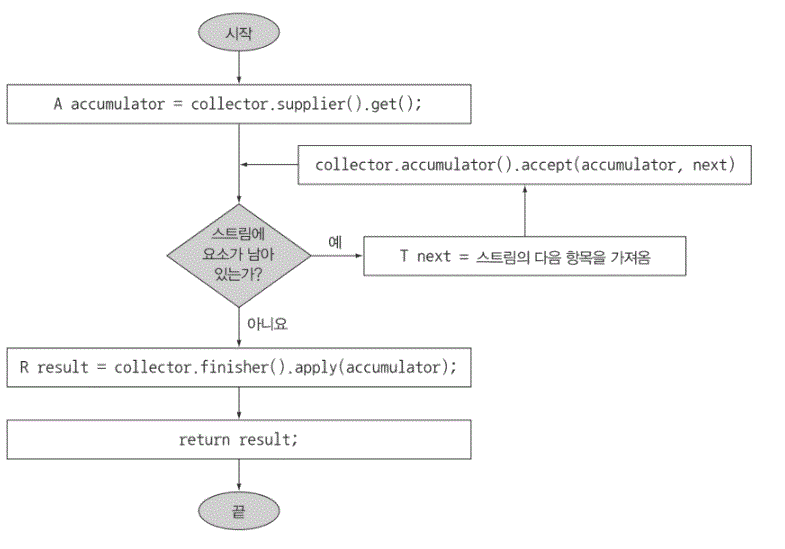
- combiner 메서드 : 두 결과 컨테이너 병합
- 리듀싱 연산에서 사용할 함수를 반환한다.
- 스트림을 병렬 처리할 때 누적자는 병렬처리과정 1에서 받은 것은 그냥 list에 추가로 add한다.
public Binaryoperator<List<T>>combiner(){ return (list1, list2) -> { list1.addAll(list2); } }
-
병렬화 리듀싱 과정에서 Combiner 메서드 활용
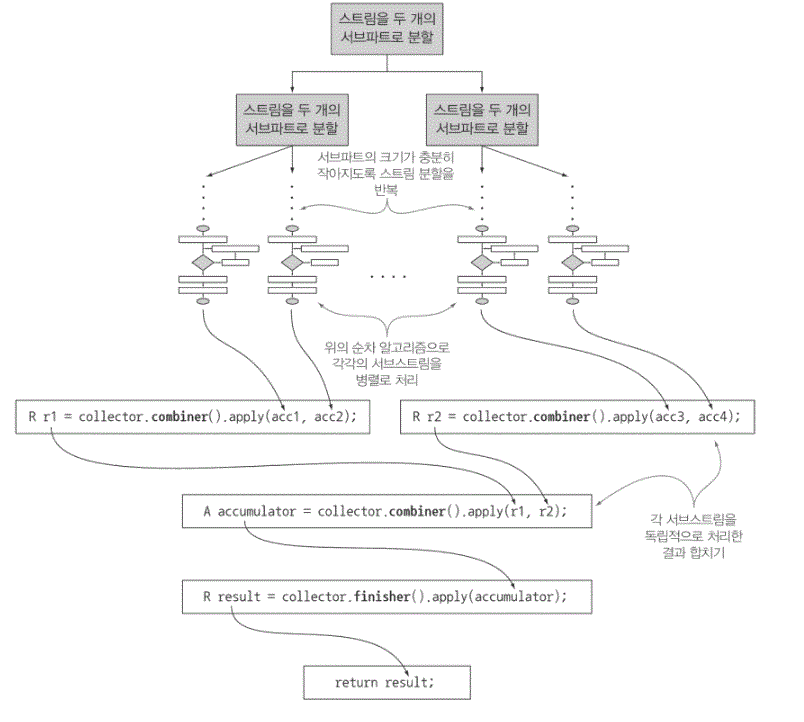
- Characteristics 메서드
- 컬렉터으 연산을 정의하는 Characteristics 형식의 불변 집합을 반환한다.
- 스트림을 병렬로 리듀스할 것인지 그리고 병렬로 리듀스한다변 어떤 최적화를 선택해야 할지 힌트를 제공한다.
- UNORDERED : 리듀싱 결과는 스트림 요소의 방문 순서나 누적 순서에 영향을 받지 않는다.
- CONCURRENT : 다중 스레드에서 accumulator 함수를동시에 호출할 수 있으며 이 컬렉터는 스트림의 병렬 리듀싱을 수행할 수 있다. UNOREDERED를 함께 설정하지 않았다면 데이터 소스가 정렬되어 있지 않은 상황에서만 병렬 리듀싱을 수행할수 있다.
- IDENTITY_FINISH : finisher 메서드가 반환하는 함수는 단순히 identity를 적용할 뿐이브로 이를생략할 수 있다.
댓글남기기